In today's digital age, vast amounts of information are exchanged in various formats, including images. However, the text embedded within images is often inaccessible for search engines, text analysis tools, and other digital applications. This limitation has given rise to the need for extracting text from images, a process that involves identifying and recognizing the textual content present within an image file.
Extracting text from images is a complex task that involves several stages, including image preprocessing, text detection, text recognition, and post-processing. Advanced techniques in computer vision, machine learning, and optical character recognition (OCR) play crucial roles in this process. As technology continues to evolve, the accuracy and efficiency of text extraction from images are constantly improving, unlocking new possibilities for data analysis, content management, and information accessibility.
Amazon Bedrock is a fully managed service that leverages advanced machine learning models to extract text and data from virtually any document or image format. It provides a seamless and scalable solution for organizations seeking to unlock the valuable information trapped within images and documents. With Amazon Bedrock, businesses can automate document processing workflows, extract insights from unstructured data, and enhance their overall data management capabilities.
Solution Architecture
The following diagram illustrates the high-level architecture. When images are uploaded into the Amazon S3 bucket, notifications are sent to a Lambda function. The Lambda function utilizes that notification to identify the newly uploaded image and sends it to the Amazon Bedrock, which extracts text from the image and stores it in the S3 bucket.
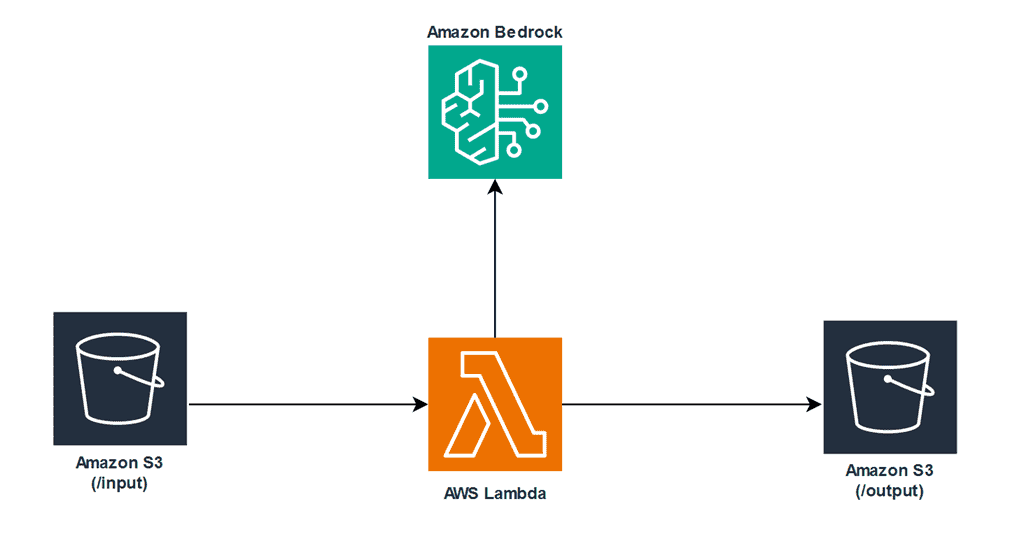
The solution includes the following components:
- Amazon S3 Bucket - We have used an Amazon S3 bucket for the image source and destination for the extracted text file.
- Anthropic's Claude on Amazon Bedrock - Amazon Bedrock offers access to foundational models from leading AI companies, including models developed by Amazon. We have used Anthropic's Claude Haiku model to extract text from images.
- Lambda Function - We have used a Lambda function to execute code which can invoke Amazon Bedrock to extract data. However, you can use any other AI models that have computer vision capabilities.
You can find complete source code on github with instruction on how to deploy it on AWS account via CDK.
After deployment, add an image to the input/ folder of Amazon S3 bucket. After few seconds, check the output/ folder of S3 bucket for extracted text.
Clean-up
If the sample application was tested in your own AWS account, it's important to clean up the resources that were created to avoid incurring charges.
Conclusion
In this post, we learned how to use Amazon Bedrock to extract text from scanned documents. However, you can also use Textract for data extraction, Amazon Textract is a machine learning (ML) service specifically designed to extracts text, handwriting, layout elements, and data from scanned documents.
Happy cloud computing.