Amazon Q Business is a conversational assistant powered by generative artificial intelligence (AI) that enhances workforce productivity by answering questions based on your data. It streamlines tasks, accelerates problem-solving, and allows you to create and share task automation applications or perform routine actions like submitting time-off requests and sending meeting invites.
In this blog post, you’ll discover how to develop a conversational assistant using Amazon Q Business to access your private data—no coding required. This method can be adapted for enterprises with diverse data sources, such as SharePoint documents, application logs in S3 buckets, or Google Drive files.
Connectors simplify synchronizing data from multiple repositories with your Amazon Q index. They can be scheduled to automatically sync, ensuring your searches always reflect the latest content securely.
For this experiment, I used personal documents (e.g., Aadhaar, PAN, Driving License, Voter ID, Bank Passbook) uploaded as scanned images to an Amazon S3 bucket. Extracting text from images can be challenging without the right tools. Initially, I used Amazon Textract, an Optical Character Recognition (OCR) service, for its robust data extraction capabilities. You can explore the source code for this approach on ServerlessLand.
However, challenges arose with diverse document types (labeled, unlabeled, and multilingual). While training Amazon Textract improved results, it required significant time and sample documents, which wasn’t practical for an experimental app. Here’s why I moved away from Textract:
- My documents were too varied to standardize.
- Custom model training required hard-to-obtain sample documents.
- Training time was too long for an experimental setup.
Instead, I turned to Amazon Bedrock, a managed service offering foundational AI models. I used Anthropic’s Claude 3 Sonnet model, which includes vision capabilities, to extract text from scanned documents. The source code for this solution is available on ServerlessLand.
With the text extracted, I built a conversational assistant atop my personal data using Amazon Q Business.
Solution Overview
The diagram below outlines the high-level architecture of this conversational assistant built with Amazon Q Business.
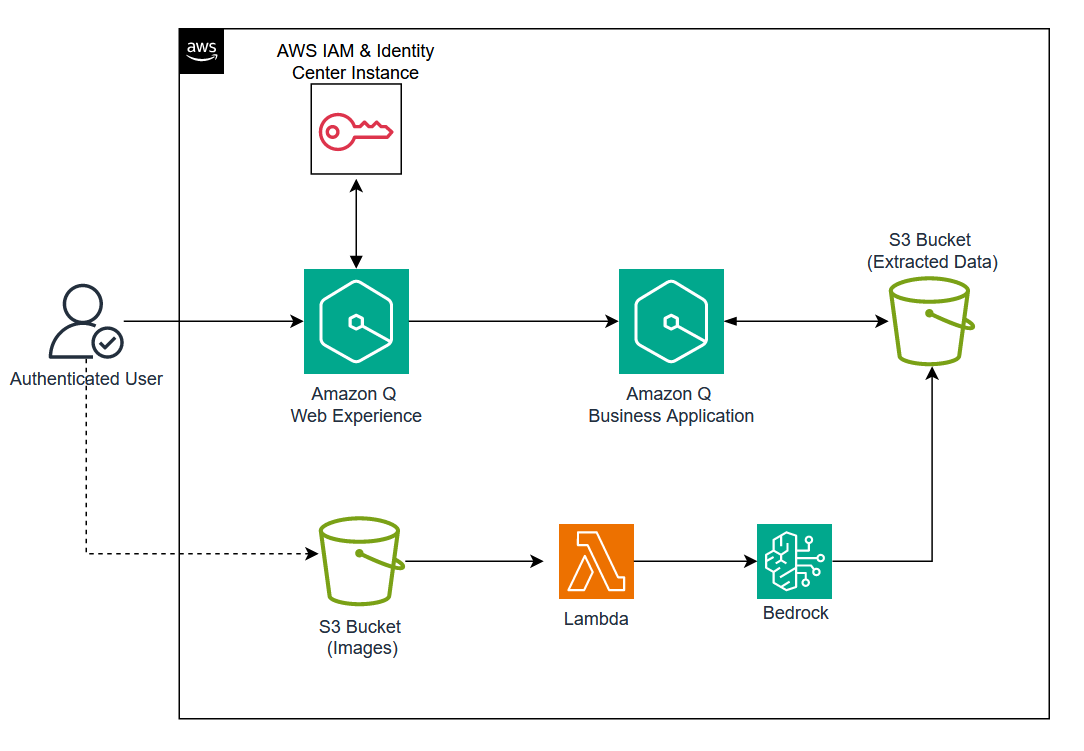
Users interact with the Amazon Q Business application through a web browser via the Amazon Q Web Experience, secured by AWS IAM Identity Center. Scanned documents are uploaded to an S3 bucket, processed by an AWS Lambda function using Amazon Bedrock for text extraction, and stored in another S3 bucket as the data source for Amazon Q Business.
Key Components:
- Amazon S3 Bucket: Stores extracted text as the data source for Amazon Q Business.
- AWS Lambda Function: Extracts text from scanned documents using Amazon Bedrock.
- Anthropic’s Claude 3 on Amazon Bedrock: Processes images within the Lambda function.
- Amazon Q Business Application: Powers the conversational assistant and web experience.
- AWS IAM Identity Center: Secures the Amazon Q Web Experience.
Configure an Amazon Q Business Application
Follow these steps to set up your application:
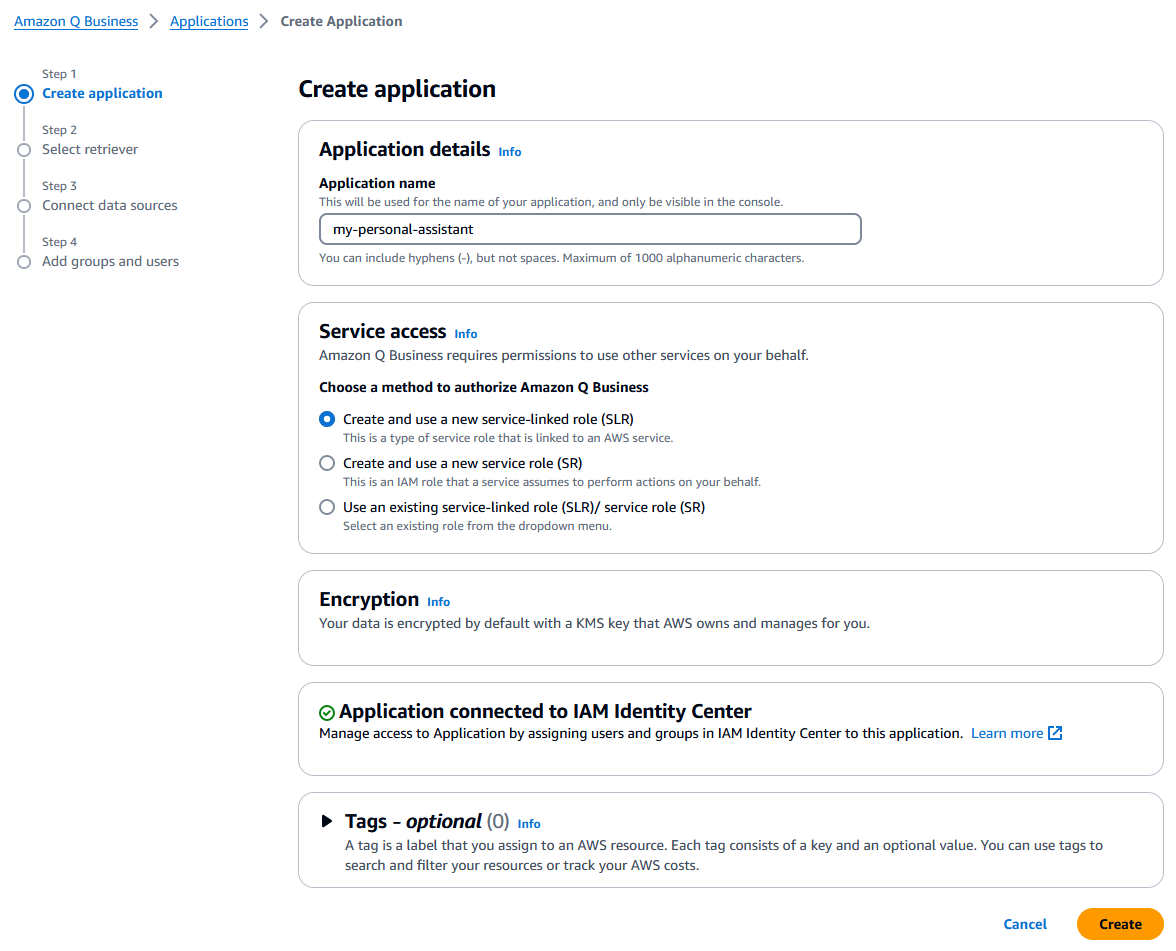
Create the Application:
- Log in to your AWS account and open Amazon Q Business.
- Click Create application.
- Enter an Application name.
- Keep the default Service Access option: “Amazon Q Business requires permissions to use other services on your behalf” (adjust if needed).
- Click Create.
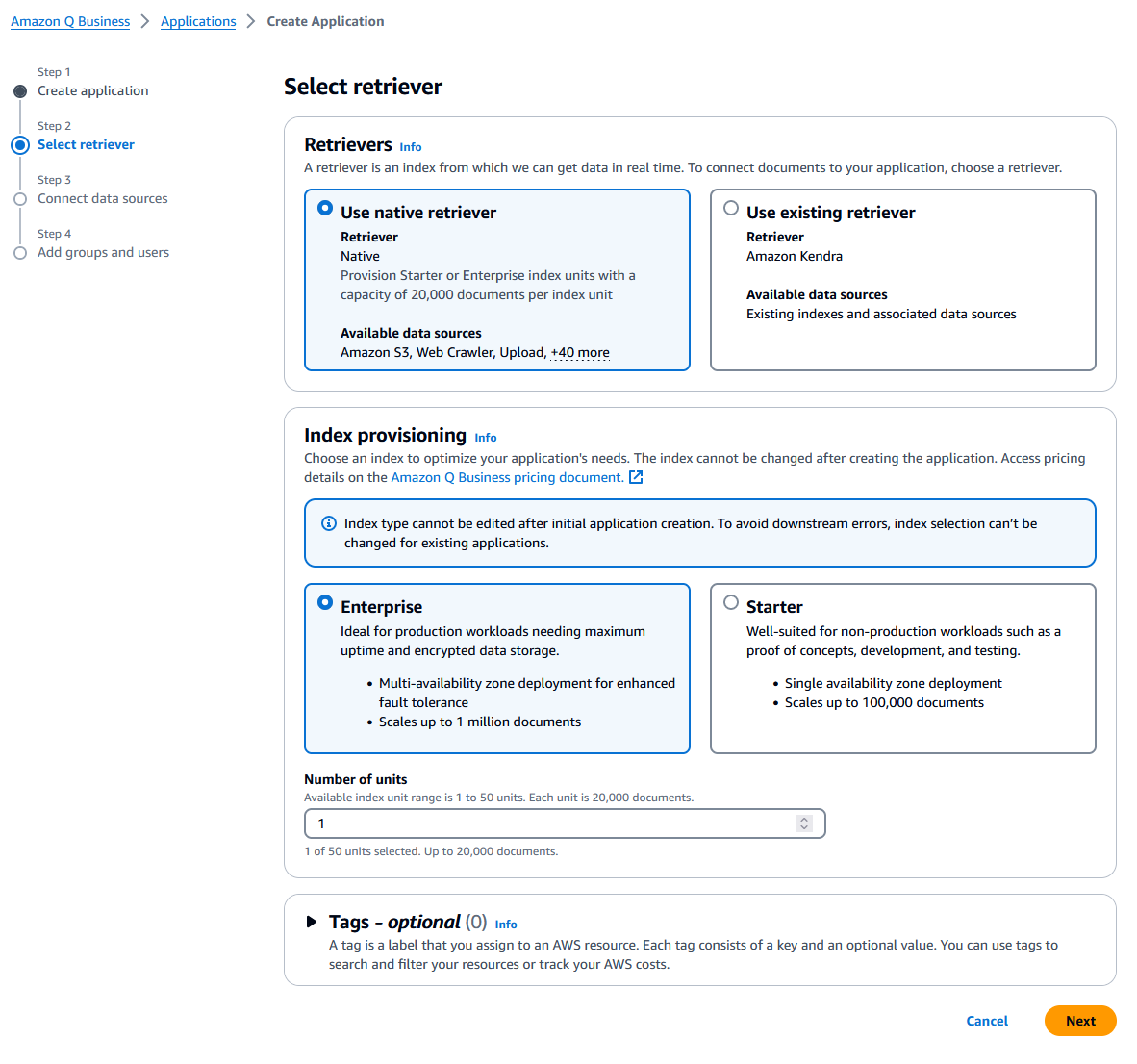
Select Retriever:
- Choose Use native retriever (default) unless you need a pre-existing Amazon Kendra index or storage for over 20,000 documents.
- Retain default Index provisioning settings.
- Click Next.
Connect Data Sources:
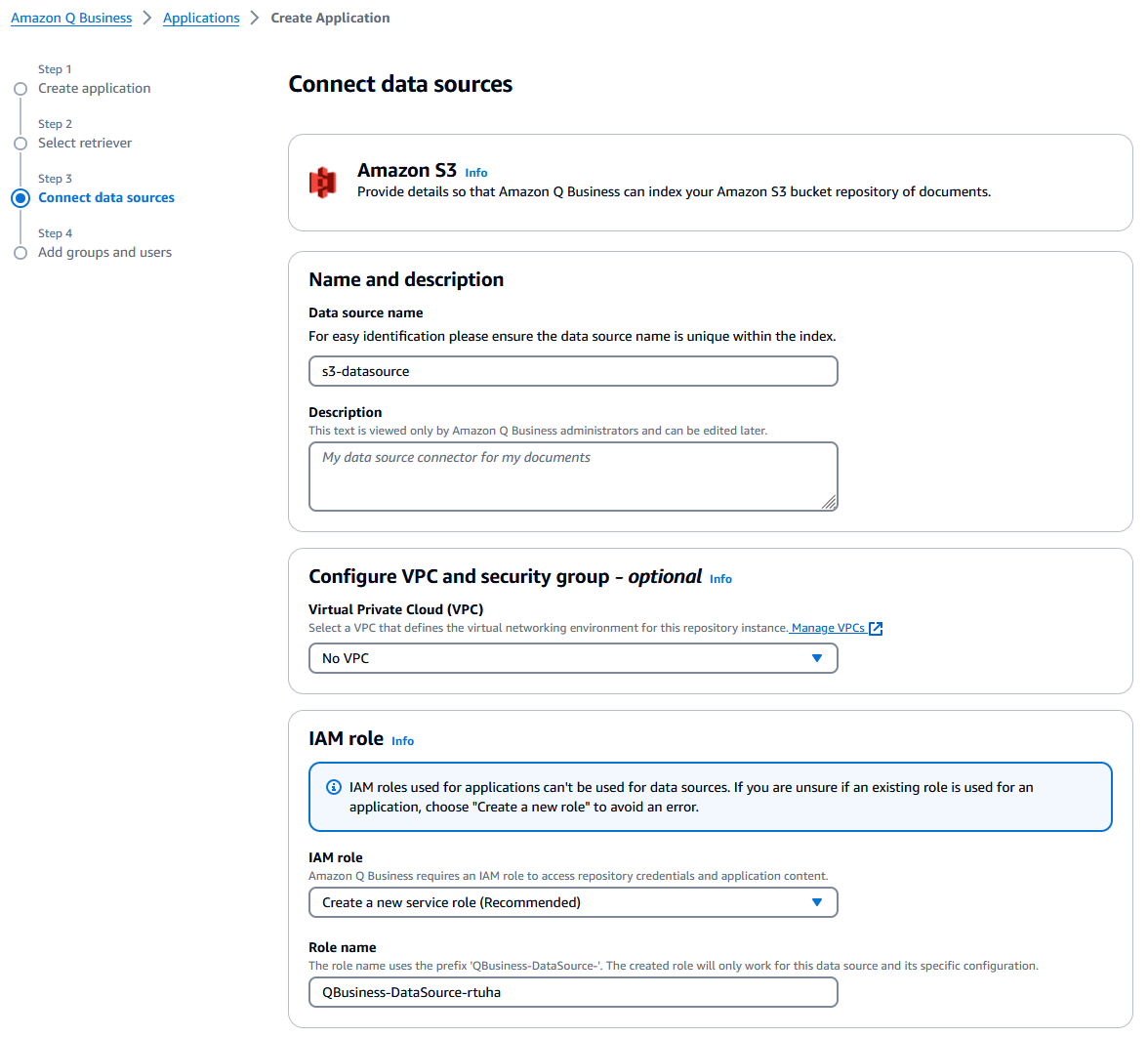
- Select Amazon S3 as the data source.
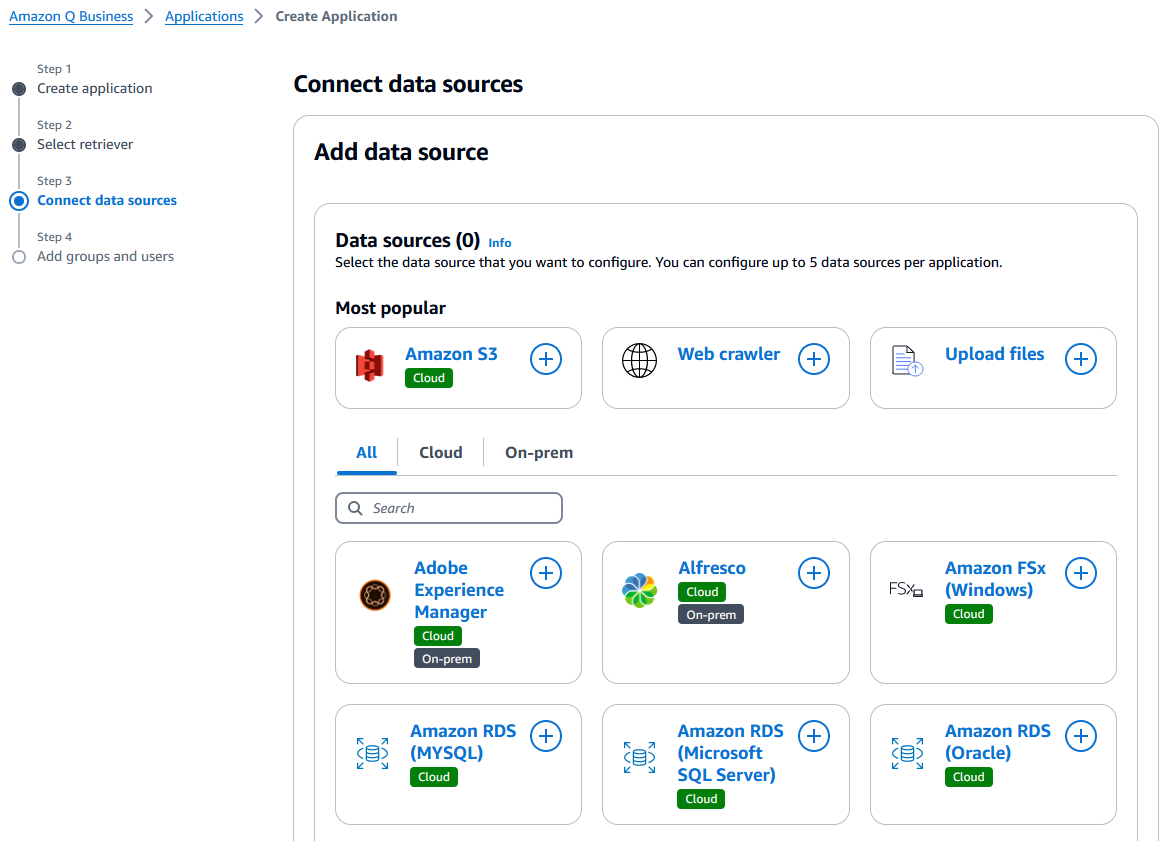
- Enter a Data source name.
- For IAM role, select Create a new service role (Recommended).
- Browse and select your S3 bucket. If your data is in a folder (e.g.,
output/), set it as the include pattern. - Set Sync mode to Full sync and Sync run schedule to Run on demand (adjust frequency as needed).
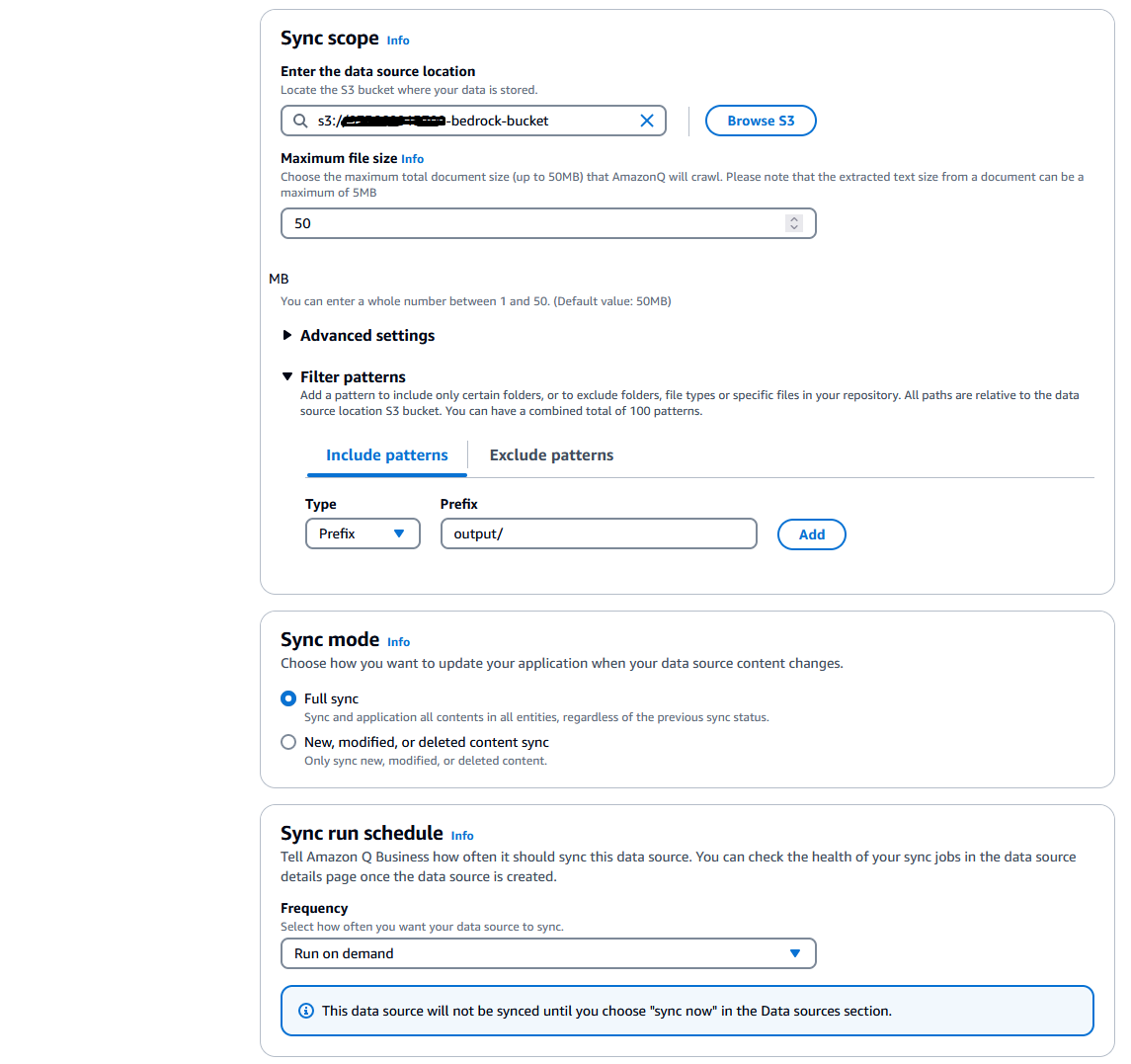
- Click Add data source, then Next.
Add Groups and Users:
- Go to the Users tab and click Add or assign users and groups.
- Select Add new users, enter details, and click Next.
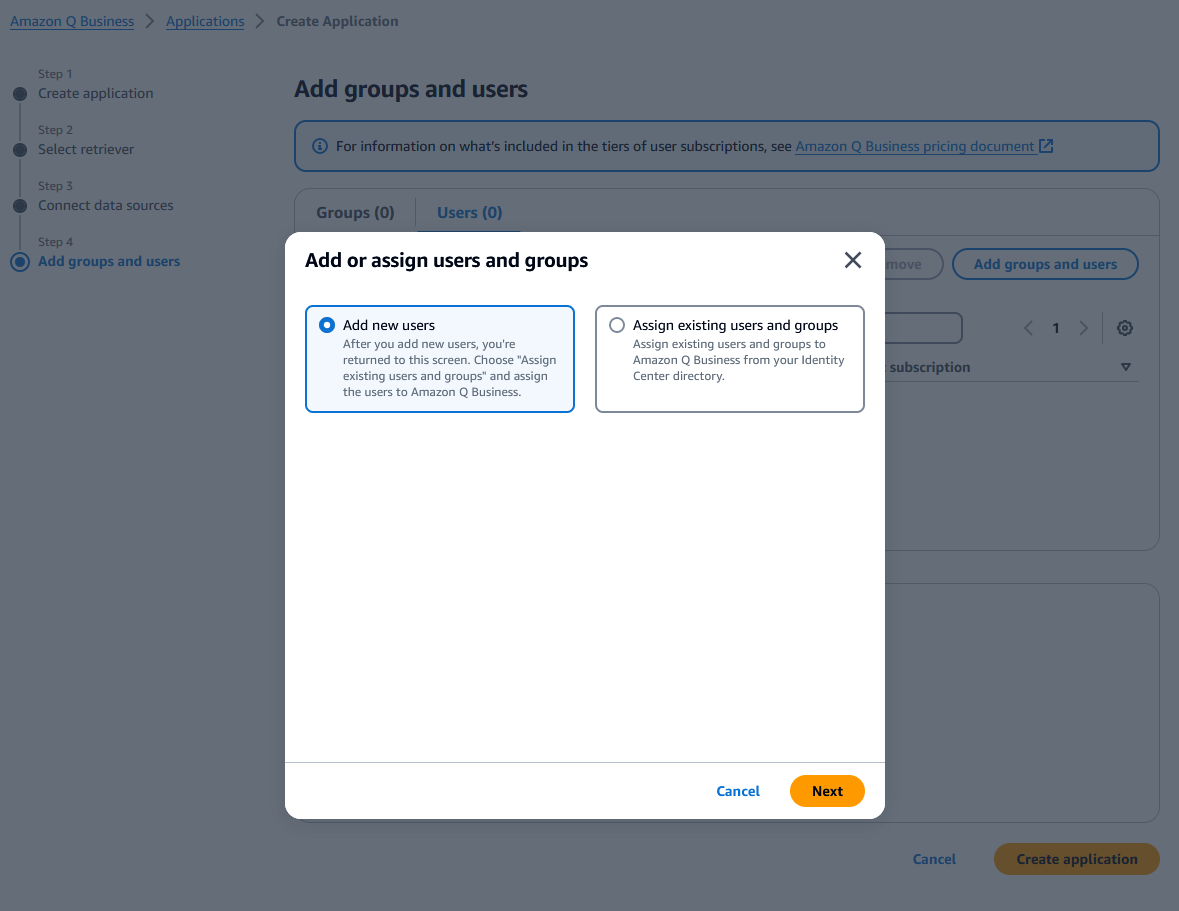
- Assign the user and click Create application.
Accept Invitation:
- Check your email for an invitation, accept it, and set up your account.

Finalize Application:
- For Web experience service access, keep the default Create and use a new service role.
- Click Create application.
Sync Data Source:
- Select your application, go to the Data source section, choose s3-datasource, and click Sync now.
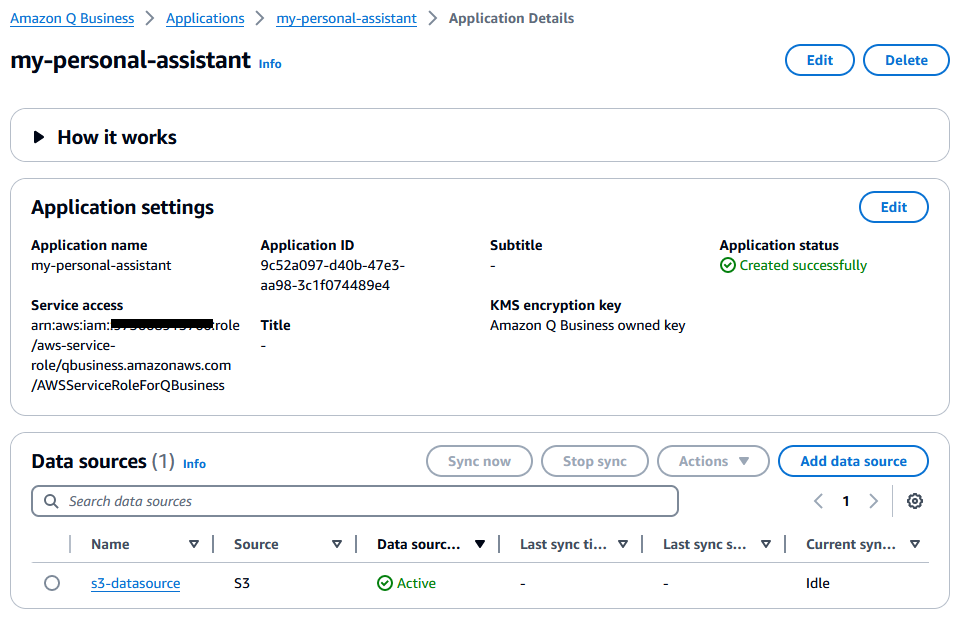
- Wait for the sync to complete.

Start Conversation:
- Return to the application, select Web experience, and log in with your credentials.
- Begin asking questions about your documents.
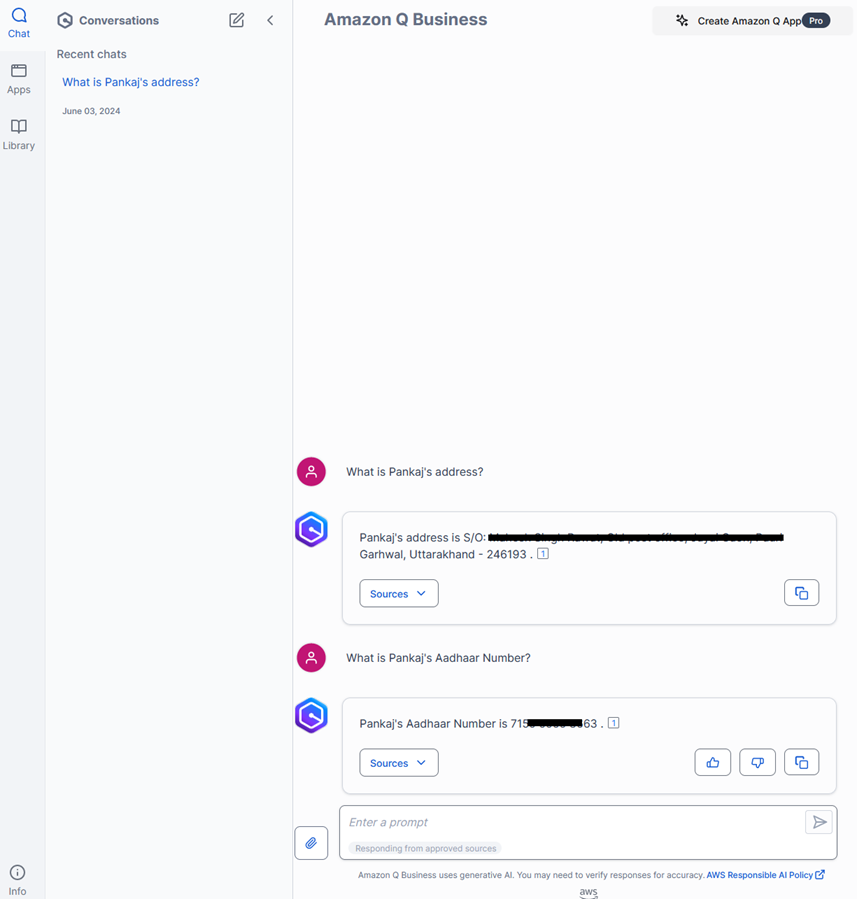
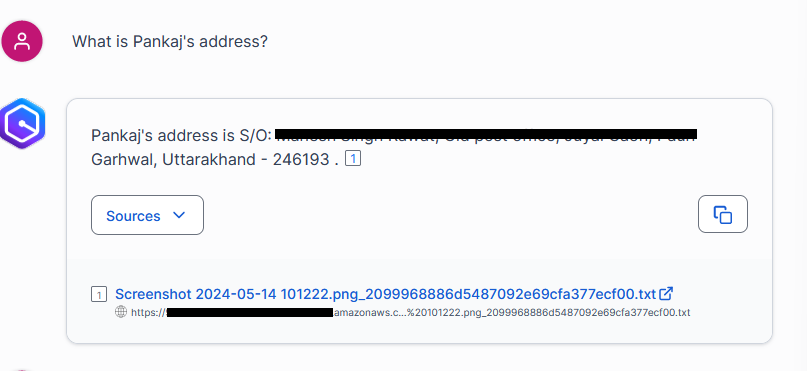
- Amazon Q Business includes source information with each response for verification.
Conclusion
Amazon Q Business lets you build a private conversational AI assistant without coding. Its connectors integrate effortlessly with your data sources, allowing natural language queries. I chose Amazon Bedrock over Textract for text extraction due to my experimental needs, but Amazon Textract excels at extracting text, handwriting, and layout elements from scanned documents in most cases.
Happy cloud computing!